
Ongoing Research
마비말 환자의 구강 구조 시각화 시스템
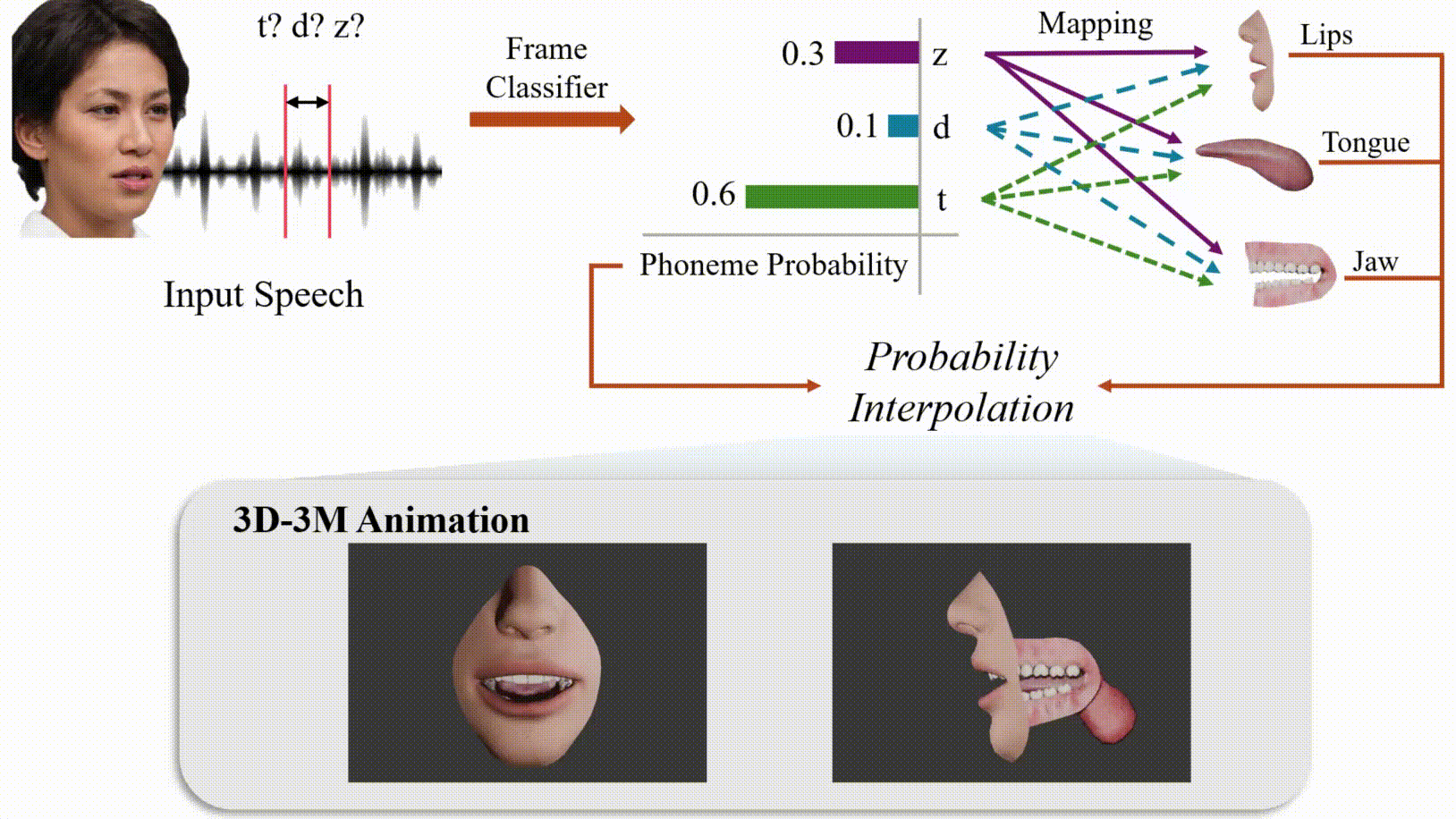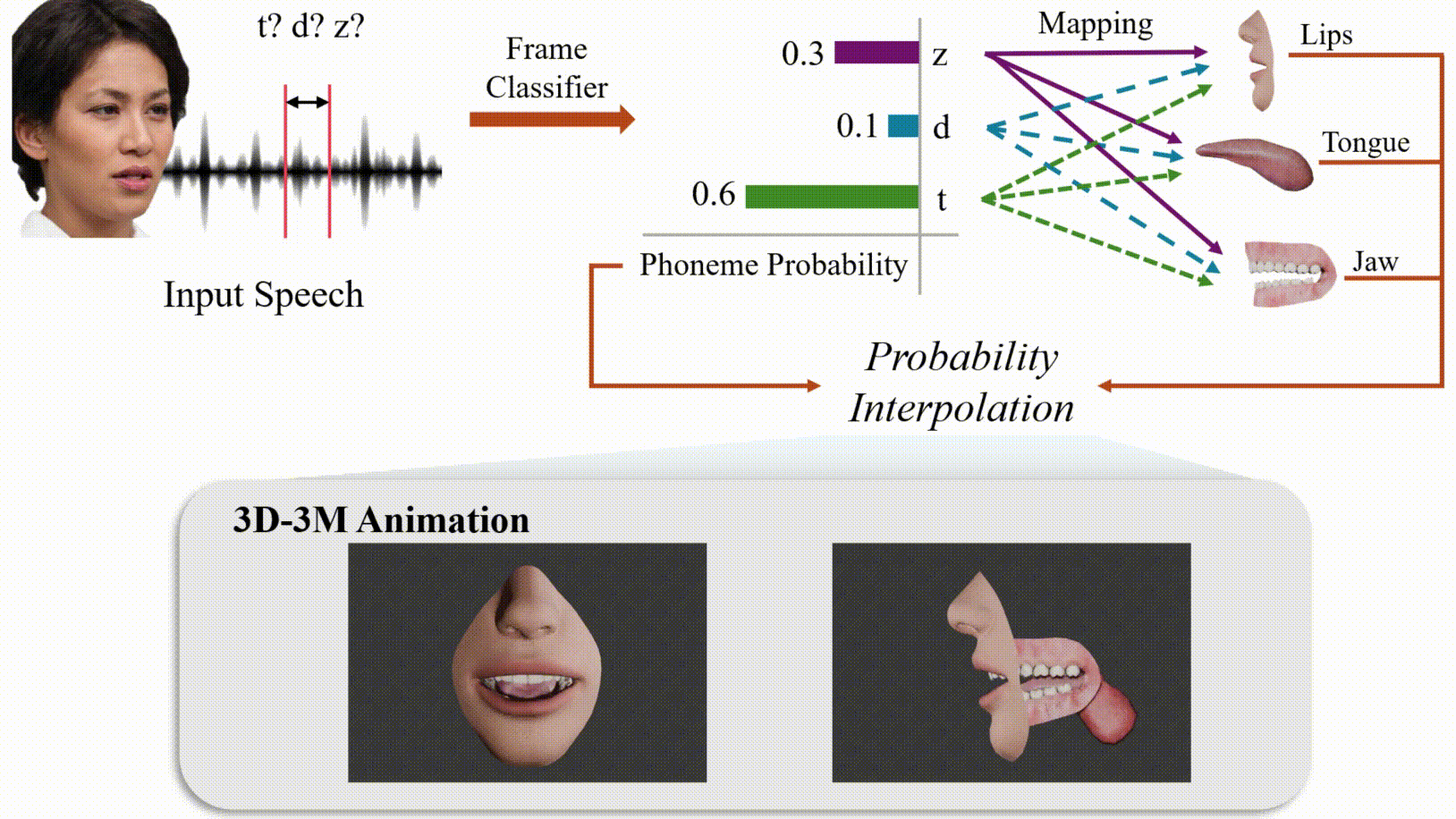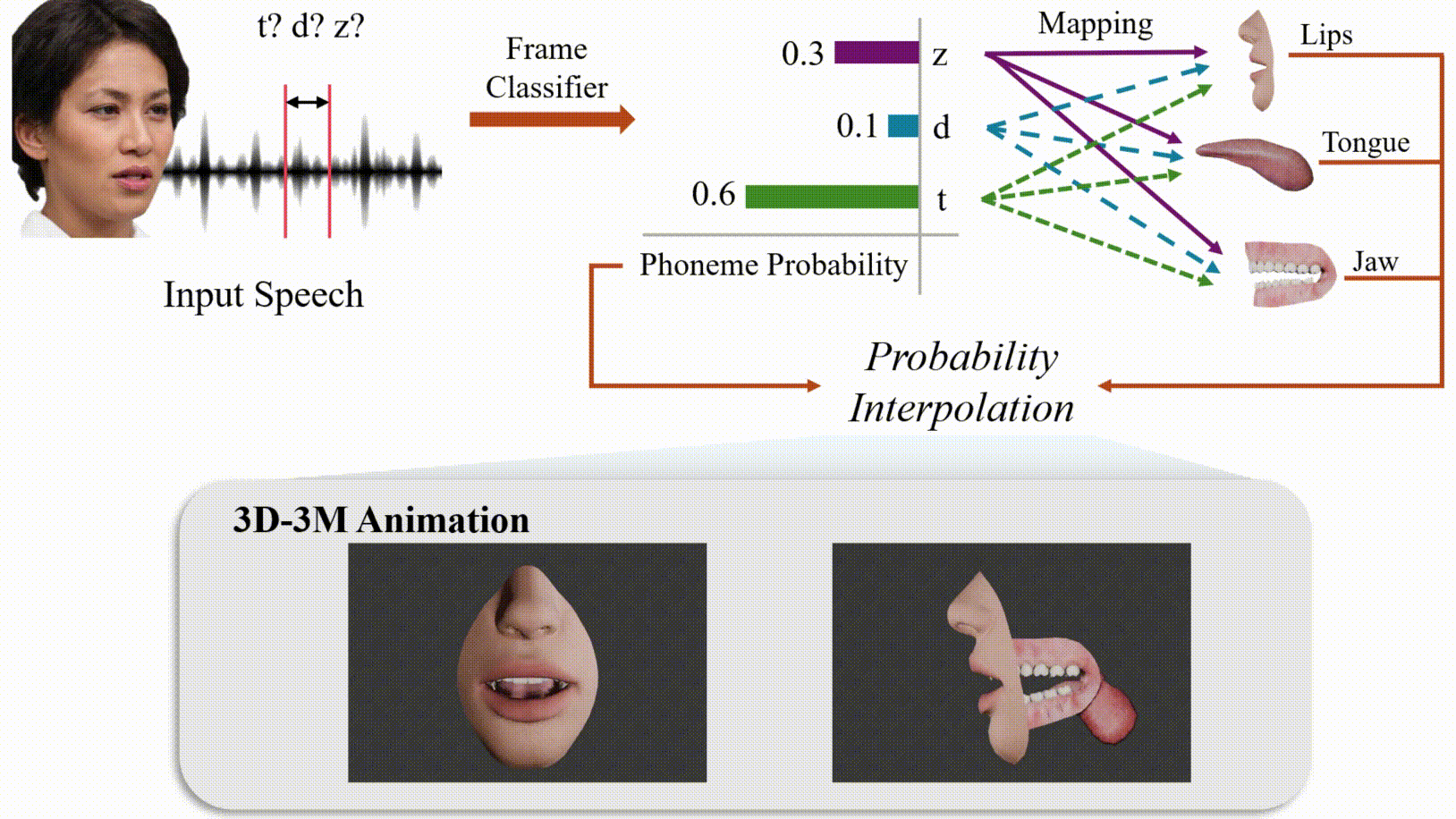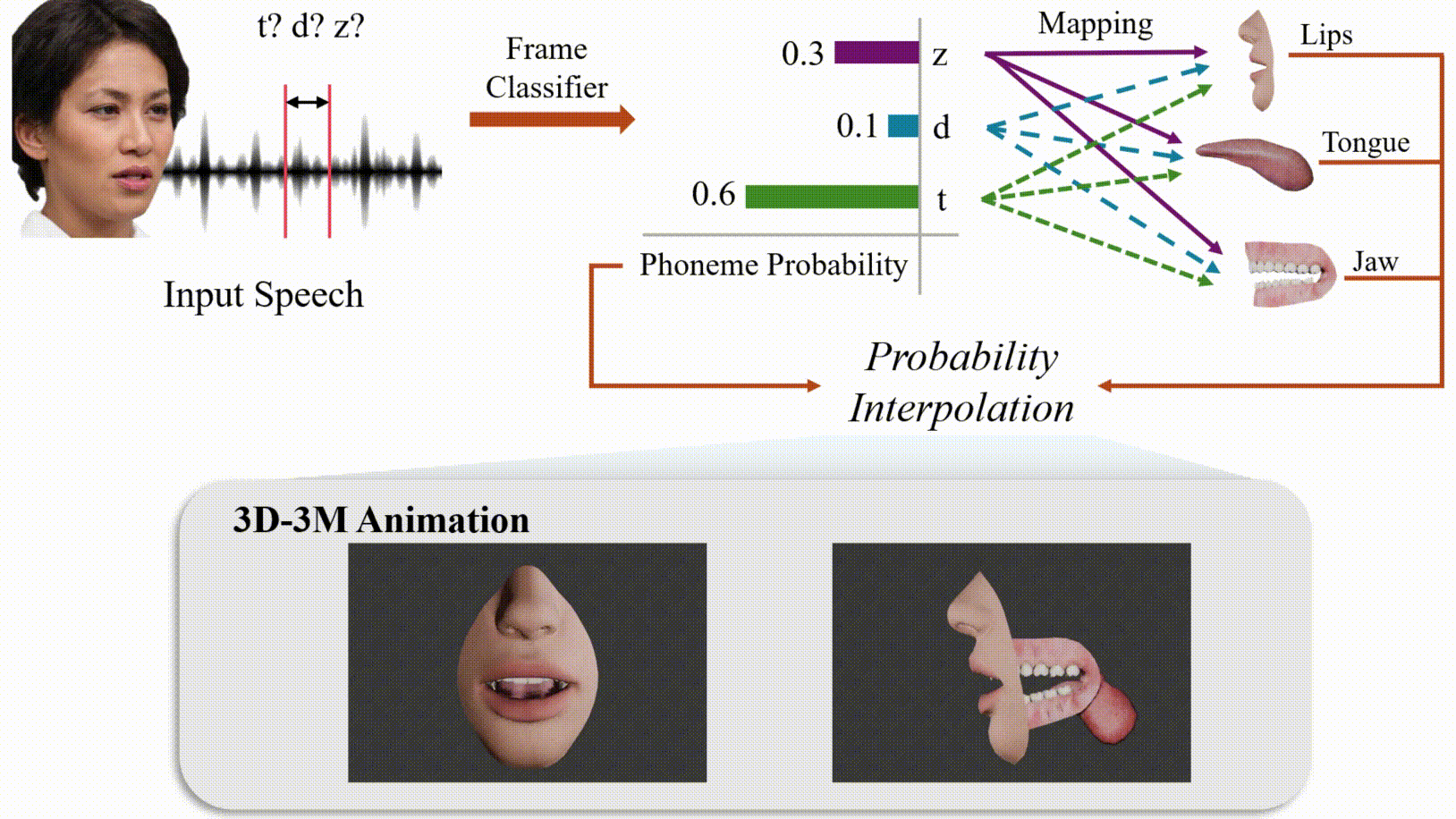
Modeling 3D oral movements is crucial for advancing speech-driven applications like speech therapy, language education, and animation. However, existing methods struggle to generalize across diverse speakers, limiting their ability to capture complex oral dynamics. To address this, we introduce the first publicly available dataset mapping phonemes to 3D parameters of the tongue, lips, and jaw, enabling anatomically accurate speech simulations. We also propose a novel approach that integrates audio features with speaker-specific adaptability to capture variations such as intonation and accent. This research lays the foundation for realistic and versatile applications in therapeutic, educational, and creative domains.
Demo: Link
멀티모달 데이터 증식 기법
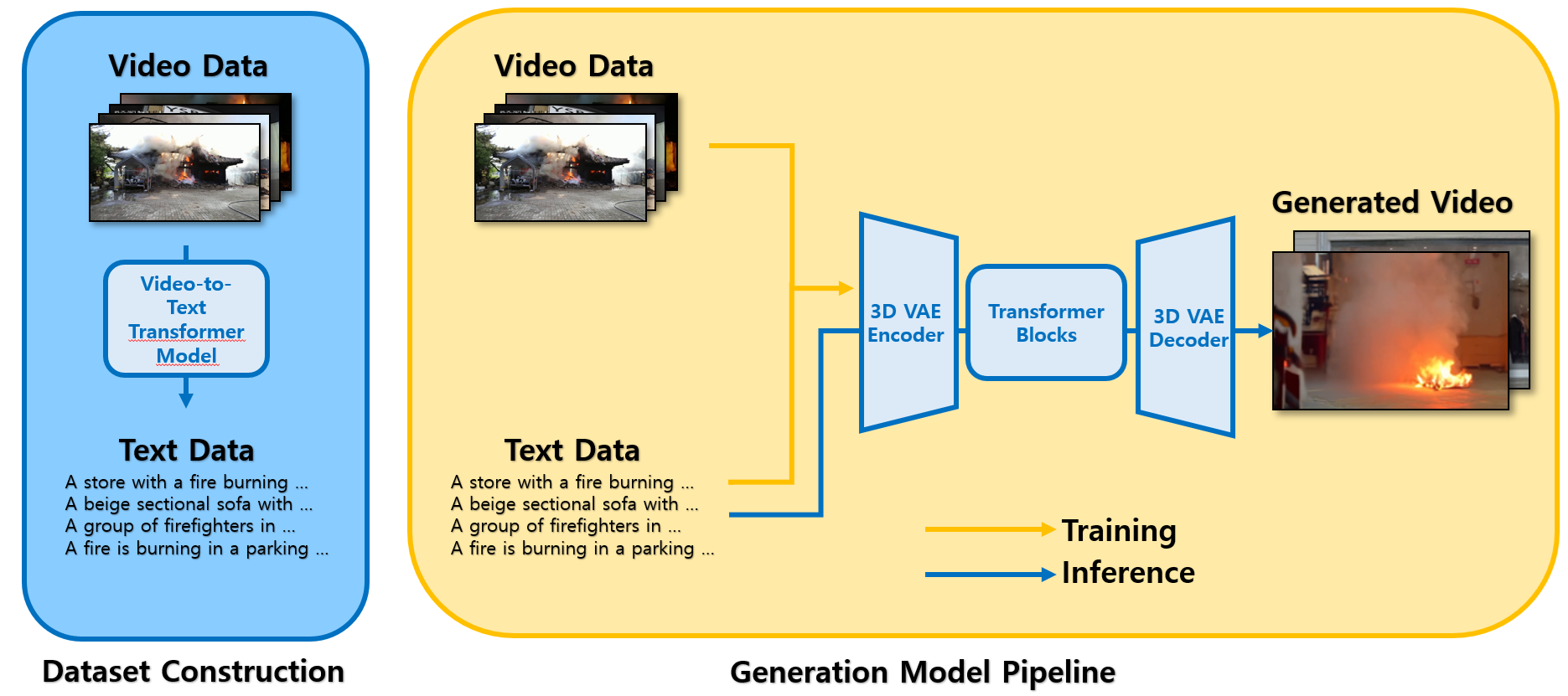
This study investigates multimodal dataset augmentation techniques for developing intelligent security and risk-response systems. It leverages generative AI models—such as diffusion models and GANs—to synthesize videos depicting various hazard scenarios (e.g., fires, falls, floods). A Transformer-based approach is then used to construct a video–text dataset, which serves as the foundation for training an advanced generative model. Finally, the trained model and accompanying text dataset are employed to augment video data for training detection models.
Real-time zero-shot 3D 복원 기법
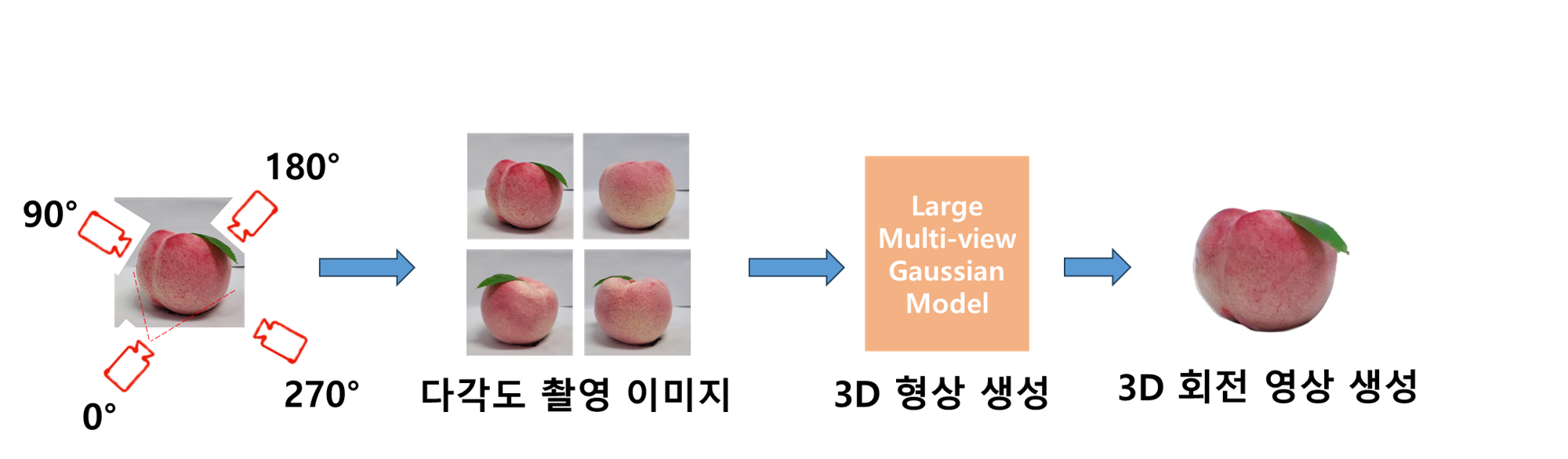
The system enables small business owners to upload videos captured on their mobile devices to a server in real time. By analyzing images taken from four key angles, it reconstructs high-quality 3D objects. Each reconstructed model stores the object’s essential features and generates an MP4 of a rotating view for visualization. This solution allows merchants to manage product information more efficiently and leverage it on e-commerce platforms. In particular, its ability to perform real-time 3D reconstruction with nothing more than simple mobile footage supports digital transformation and revitalizes online commerce.
Single Image Deraining
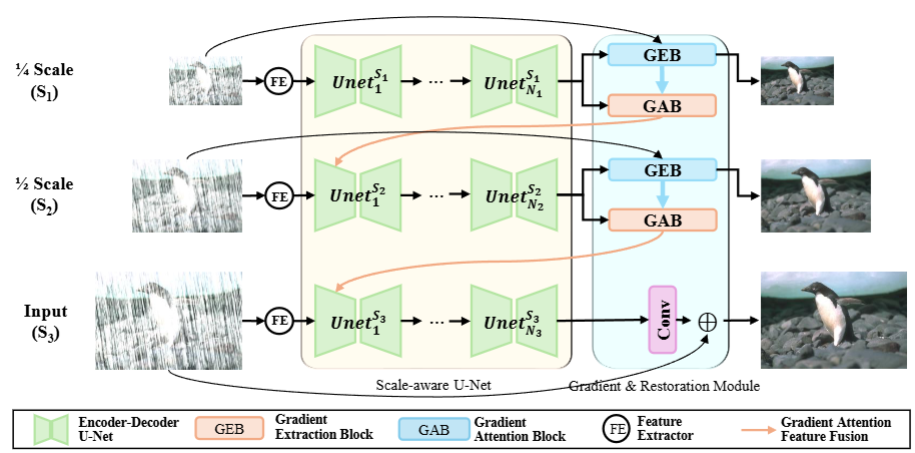
Efficient single-image deraining is critical for real-time applications, yet many methods face high memory demands. Our research introduces RARo, a scale-aware CNN designed for low computational cost and high-performance deraining. By utilizing Gradient Extraction and Attention Blocks across multiple scales, RARo effectively captures diverse rain streak features. This approach, combined with a gradient-based loss using Sobel filters, ensures high-quality restoration with strong memory efficiency, making it ideal for real-time tasks.
Completed Research
유해미디어 과제 시스템 데모
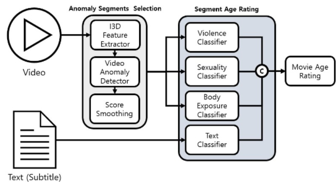
This is a demo system that enables users to upload a video and, by comprehensively leveraging visual, audio, and textual information, automatically classifies its final rating while presenting detailed information.
무인자율주행 자동차용 비전 시스템

Autonomous vehicle navigation has gained wide attention as the key technical component to develop Unmanned Ground Vehicles. So far, the lack of simulation tools has deterred efficient development of the navigation algorithms that can be decoupled from the field test. We have developed a powerful vehicle navigation simulator that is connected with earth map APIs supporting GPS coordinate system.
비디오 이벤트 검출 기법
We rigorously analyze and combine a large set of low-level features that capture appearance, color, motion, audio and audio-visual co-occurrence patterns in videos. We also evaluate the utility of high-level (i.e., semantic) visual information obtained from detecting scene, object, and action concepts. Further, we exploit multimodal information by analyzing available spoken and videotext content using state-of-the-art automatic speech recognition (ASR) and video text recognition systems. We use a twostep strategy for combining these diverse streams: features modeling similar information (such as motion) are combined through a fast multiple kernel learning (MKL) framework.
Periocular 생체 정보를 이용한 사용자 인식 방법
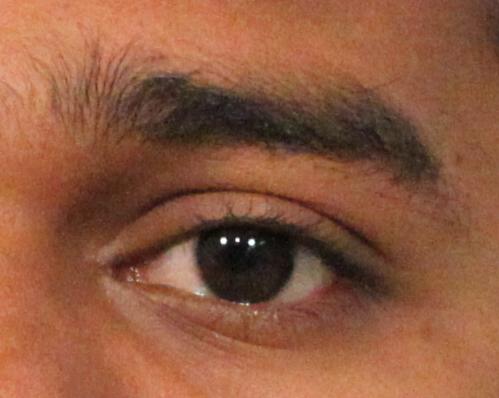
The term periocular refers to the facial region in the immediate vicinity of the eye. Acquisition of the periocular biometric is expected to require less subject cooperation while permitting a larger depth of field compared to traditional ocular biometric traits (viz., iris, retina, and sclera). In this work, we study the feasibility of using the periocular region as a biometric trait. Global and local information are extracted from the periocular region using texture and point operators resulting in a feature set for representing and matching this region.
용의자 자동 검색을 위한 감시 카메라 시스템

We propose a Visual Search Engine (ViSE) as a semi-automatic component in a surveillance system using networked cameras. The ViSE aims to assist the monitoring operation of huge amounts of captured video streams, which tracks and finds people in the video based on their primitive features with the interaction of a human operator. We address the issues of object detection and tracking, shadow suppression and color-based recognition for the proposed system.
Development of a real-time image processing system for non-destructive evaluation (NDE)

Magneto-optic Imaging (MOI) is a non-destructive evaluation technique that is being used increasingly in aircraft inspection. In order to address the problem of interpreting a large volume of inspection data and subjectivity of manual interpretation, this paper presents an automated rivet inspection algorithm that performs filtering, rivet detection, and classification using MOI. The algorithms developed are also implemented on a Digital Signal Processor (DSP) board for real time performance. Initial results of implementing the algorithm are presented.
Face recognition at a distance using PTZ camera

Face images have a low resolution when they are captured at a distance (say, larger than 5 meters) thereby degrading the face matching performance. To address this problem, we propose an imaging system consisting of static and pan-tilt-zoom (PTZ) cameras to acquire high resolution face images up to a distance of 12 meters. We propose a novel coaxial-concentric camera configuration between the static and PTZ cameras to achieve the distance invariance property using a simple calibration scheme. We also use a linear prediction model and camera motion control to mitigate delays in image processing and mechanical camera motion. Our imaging system was used to track 50 different subjects and their faces at distances ranging from 6 to 12 meters.
3D face reconstruction from video

Surveillance videos are generally of low resolution containing faces mostly in non-frontal poses. Consequently, face recognition in video poses serious challeng es to state-of-the-art face recognition systems. Use of 3D face models has been suggested as a way to compensate for low resolution, poor contrast and non-fr ontal pose. We propose to overcome the pose problem by automatically (i) re constructing a 3D face model from multiple non-frontal frames in a video, (ii) generating a frontal view from the derived 3D model, and (iii) using a commercial 2D face recognition engine to recognize the synthesized frontal view.
Object recognition and Image retrieval
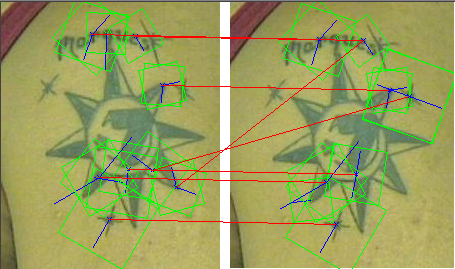
Among various approaches to image retrieval, scale space representation and local keypoint deors have been shown to be a promising approach. Even though the concept of scale space representation has been known for a long time, it has now gained prominence as a powerful method for image retrieval mostly due to the invention of the Scale Invariant Feature Transform (SIFT). We will review the characteristics of the scale space operation and provide an extended method of scale space operation that significantly improves the image matching accuracy in the context of image retrieval.
Aging modeling for face recognition

Facial aging is a complex process that affects both the 3D shape of the face and its texture (e.g., wrinkles). These shape and texture changes degrade the performance of automatic face recognition systems. However, facial aging has not received substantial attention compared to other facial variations due to pose, lighting, and expression. We propose a 3D aging modeling technique and show how it can be used to compensate for the age variations to improve the face recognition performance. The aging modeling technique adapts view-invariant 3D face models to the given 2D face aging database.
Facial mark based face recognition
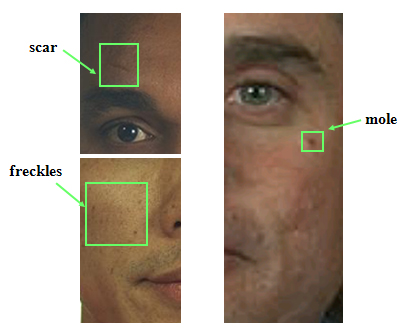
Facial marks can also be useful to differentiate identical twins whose global facial appearances are very similar. The similarities found from soft biometrics can also be useful as a source of evidence in courts of law because they are more deive than the numerical matching scores generated by a traditional face matcher. We propose to utilize demographic information (e.g., gender and ethnicity) and facial marks (e.g., scars, moles, and freckles) for improving face image matching and retrieval performance. An automatic facial mark detection method has been developed that uses 1) the active appearance model for locating primary facial features (e.g., eyes, nose, and mouth), 2) the Laplacian-of-Gaussian blob detection, and 3) morphological operators.
Janus, 미국 고등정보연구계획국(IARPA)연구과제
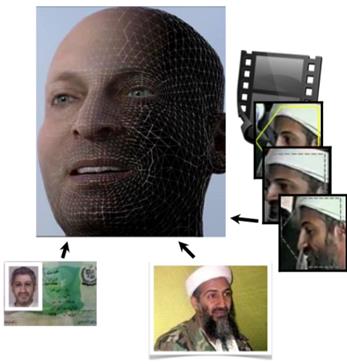
USC ISI(미국), USC(미국), OU(이스라엘), U of Firenze(이탈리아), TensorVision(미국)을 포함하는 국제 공동 연구팀과 미국 고등정보연구계획국(IARPA)에서 주관하는 Janus 사업에 참여하여 총 연구비 $11,947,626/4년 중 $400,000/4년 규모로 얼굴 마크, 겉보기 속성 등에 관한 세부 연구를 수행 중에 있다. Janus는 얼굴 인식 관련 연구 과제로 총 4년간 다양한 포즈, 조명, 표정 변화에 강인한 얼굴 인식 기술을 개발하는 것을 목표로 한다.
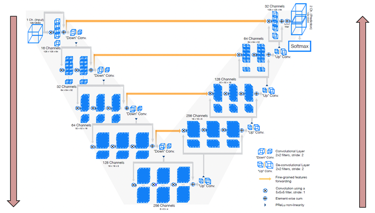
3D depth를 복원하는 딥러닝 기반 기술 개발 시스템
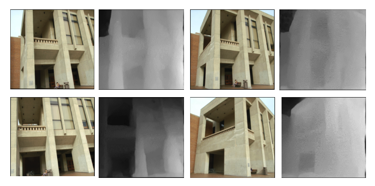
3D depth를 복원하는 딥러닝 기반 기술 개발
무인자율주행 자동차용 비전 시스템
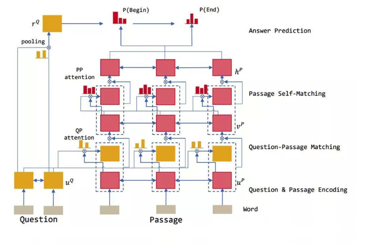
기존의 단순히 주가 움직임의 예측에 대한 시스템이 아니라 사진과 같이 사용자의 질문을 이해하고 그에 따른 인과 관계를 추론함으로써, 질의에 해당하는 답변을 근거와 함께 제공하는 고차원 시스템 개발을 목표로함.
딥러닝을 활용한 금융투자 QA 시스템 개발
Autonomous vehicle navigation has gained wide attention as the key technical component to develop Unmanned Ground Vehicles. So far, the lack of simulation tools has deterred efficient development of the navigation algorithms that can be decoupled from the field test. We have developed a powerful vehicle navigation simulator that is connected with earth map APIs supporting GPS coordinate system.
딥러닝 기반 금형 보정 기술 개발
프레스 금형 작업 후 제품의 탄성 변형에 의하여 설계된 수치의 제품이 얻어지지 않으며, 이에 대한 보정 작업은 시행착오 및 전문가의 경험과 직관에 의존하여 왔음. 과거 보정 데이터 및 머신 러닝 기법을 이용한 금형 보정 기술을 개발함으로써, 금형 수정 회수를 감소시켜 공수 절감.
과거 보정 이력 데이터에 기반하여 머신러닝 기법을 통한 금형 보정 기술 개발. 금형 보정량을 3차원 제품 모델을 이용하여 표출하는 것을 목표로 하며, 이를 위하여 과거 유사 제품 및 공법 검색, 보정 필요 부위 이름 예측, 보정 필요 부위 3차원 모델에 표출, 변형 예측 기반 금형 보정치를 3차원적 표출 기술 개발을 단계적으로 수행함.